當我們一再聽說,人工智慧應用未來將會深入人類各個層面的生活領域時,是什麼技術支持了這樣的發展?面對未來人工智慧的普及,我們應該放心享受技術帶來的便利,或是必須更加警惕?
人工智慧是指由人所創造的機器,可以表現出具備某些人類知性的行為,例如感知、學習、記憶、推理、判斷、決策。近年Google AlphaGo打敗人類棋王之後,大家才驚覺“原來機器已經可以這麼聰明了”!事實上,人工智慧技術並不是突然取得重大進展的,以目前主流的“深度學習” (Deep Learning)技術而言,其本源 “人工神經網路” (Artificial Neural Network) 的數學理論早自上個世紀40年代即已提出;到70年代時,主要原理技術皆已成熟,只是電腦硬體的運算速度及儲存能力,無法處理如此大量的運算資料因而難以實用。本世紀開始以後,由於電腦硬體的運算及儲存能力的大幅躍進,加上NVIDIA公司推出利用電腦顯示晶片進行大規模平行計算的CUDA技術,使得人工神經網路變為可行,於是相關研究與應用一下子又復活起來。
人工神經網路的操作分為“訓練”(training)及“推論”(inference)兩個步驟,前者需要反覆使用訓練樣本正向輸入網路模型,接著計算輸出的預期值與實際值差距,再從輸出端反向對網路模型內各個神經元鏈接的權重值進行校正(稱為反向傳播法),當輸出實際值逐漸向預期值靠近並收斂,網路模型的“學習”便完成,可以用於推論。舉例來說,當我們拿五類車輛圖片共一萬張訓練一個人工神經網路模型,當訓練完成時,這個網路模型憑藉反覆校正神經鏈結 “學會”了各式車輛特徵,因此我們輸入訓練樣本以外的其他車輛圖片時,該網路模型就能很快推論出圖片內的車輛是五類車輛中的哪一類。但如果我們拿一張飛機圖片輸入這個網路,是不會被辨認出來的,因為飛機不在訓練樣本內,其特徵並未在訓練中被網路學會。
以目前技術來說,人工神經網路的訓練需要極龐大的運算能力及記憶體,而且在不同的應用情境下,神經元鏈接權重都需要更新,也就是需要(局部或全部)再次訓練,這只有裝備多顆顯示晶片,專門用於人工神經網路模型訓練的電腦主機才能做到。如果只執行推論工作,雖然仍然有相當的計算量,但是只要把合適的加速電路(主要是以平行運算方式幫忙計算矩陣元素的乘法及加法)整合進一般的嵌入式電腦系統晶片中,如手機或無人機之類的設備就可以具備特定AI功能。在國研院半導體中心的人工智慧系統開發實驗室,我們準備了各種用於人工神經網路模型建立及加速電路開發與驗證的設備,可以提供學校老師及同學進行人工智慧系統晶片的開發實作。
由以上所述,我們可以瞭解,目前可應用的人工智慧技術其實只是並未脫離當代電腦技術的本質:由人類開發數學模型,並使其操作於電路系統上。各種令人炫目的技術,其實展現的是自科學家及工程師們的人類智慧結晶,目前AI只是一種工具,其自我進化至全面超越人類的科幻情境離我們還很遙遠。我們更該關心的是,人類將如何利用人工智慧技術影響其他人類的生活-無論是光明面或是黑暗面,這是人如何使用工具的問題。
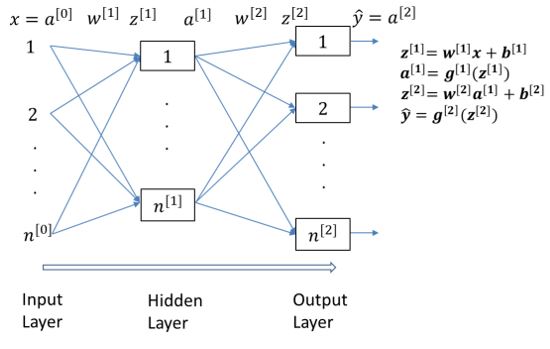
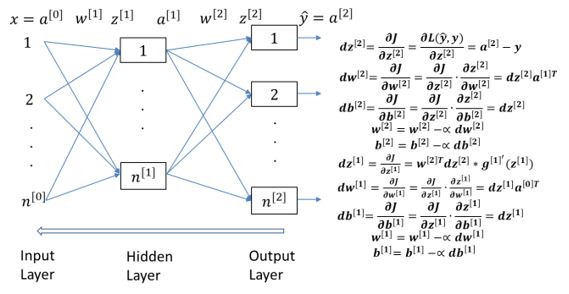
▲ 人工神經網路的正向輸入(左)與反向校正(右)運算,一次訓練需要使用多筆訓練樣本,執行大量次數的輸入及校正運算,而推論只需要用檢驗樣本執行一次輸入運算。
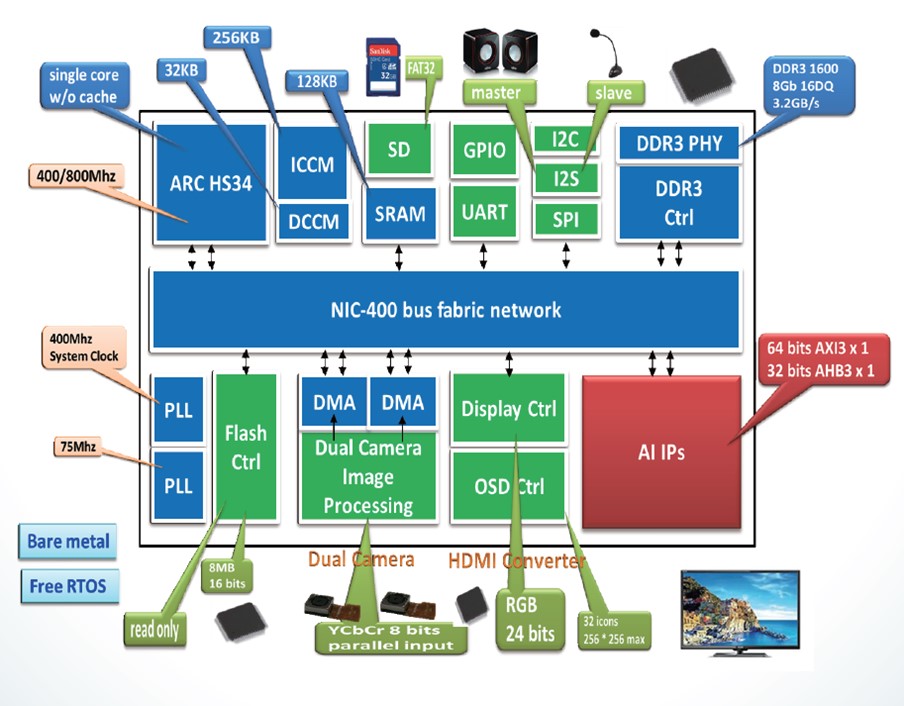
▲ 國研院半導體中心規劃的人工智慧系統晶片。除了記憶體與匯流排要求資料傳輸速度更快,設計上與一般系統晶片相當近似。圖中AI加速電路(AI IPs)的設計是重點。